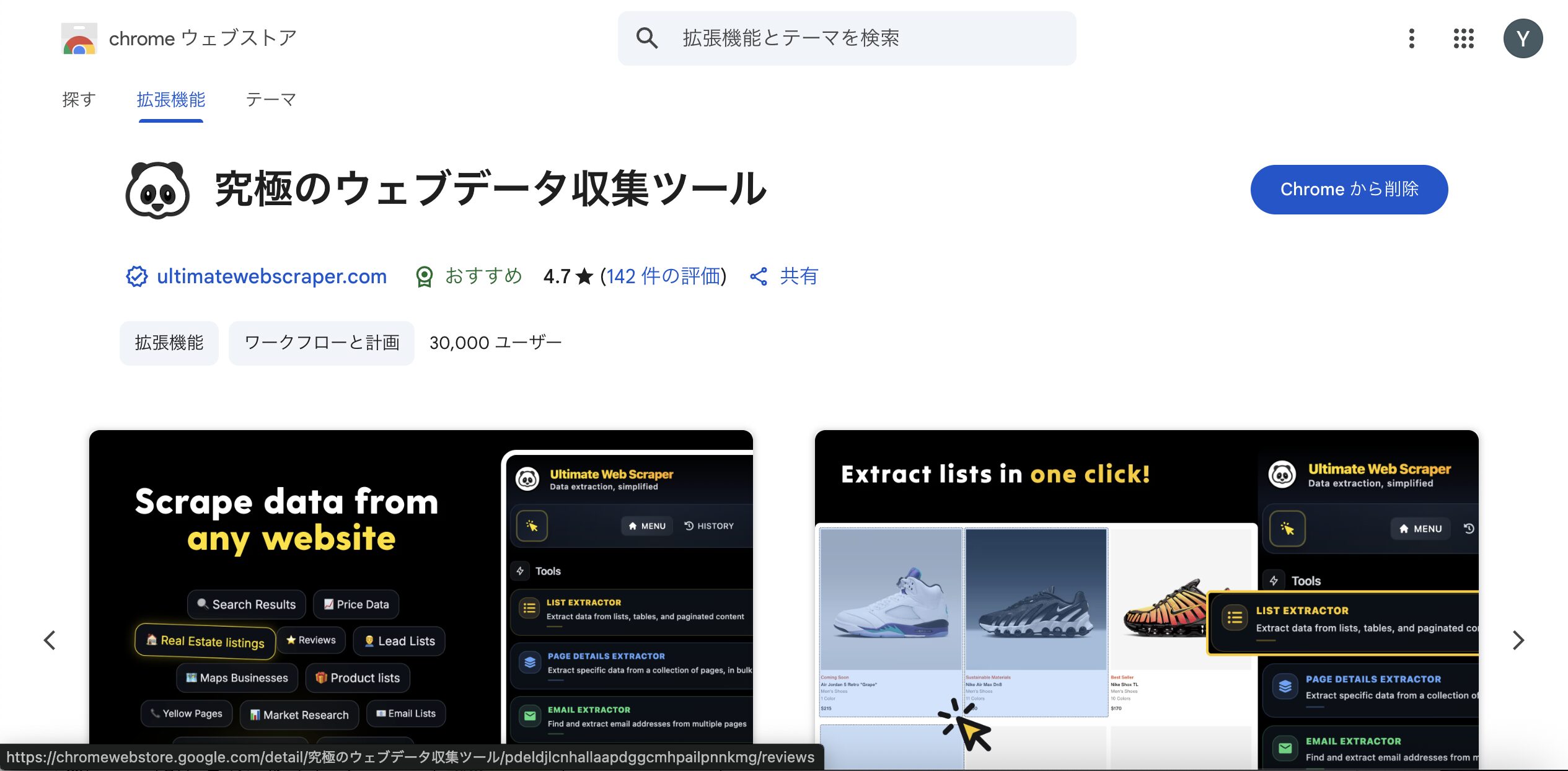
この記事でわかること: Ultimate Web Scraperの基本的な使い方から高度な活用方法、料金プラン、インストール・アクティベーション手順まで、初心者でも理解できるよう詳しく解説します。
Ultimate Web Scraperとは?なぜ今必要なのか
現代のビジネスにおいて、Webからのデータ収集は欠かせない作業となっています。競合調査、リード生成、価格比較、市場調査など、様々な場面でWebサイトからのデータ抽出が必要になります。
Ultimate Web Scraper(旧PandaExtract)は、プログラミング知識不要で誰でも簡単にWebサイトからデータを抽出できるChrome拡張機能のスクレイピングツールです。ワンクリックでテキスト、画像、メールアドレス、リンクなどを自動収集し、CSV、Excel、Google Sheetsなどの形式で出力できます。
なんだか怪しい名前をしていますが、めちゃくちゃ使えるツールなんです。笑
なぜUltimate Web Scraperが選ばれるのか?
選ばれる理由を簡単にまとめると以下の通りになります!
- ノーコード:プログラミング知識不要で誰でも使える
- 高精度AI搭載:人工知能による正確なデータ抽出
- ワンクリック操作:マウスクリックだけで簡単データ収集
- 多様な出力形式:CSV、Excel、Google Sheetsに対応
- 買い切り型:月額料金なしの永続ライセンス
Ultimate Web Scraperの5つの主要機能
ここからは、主要な機能5つをまとめていきます!
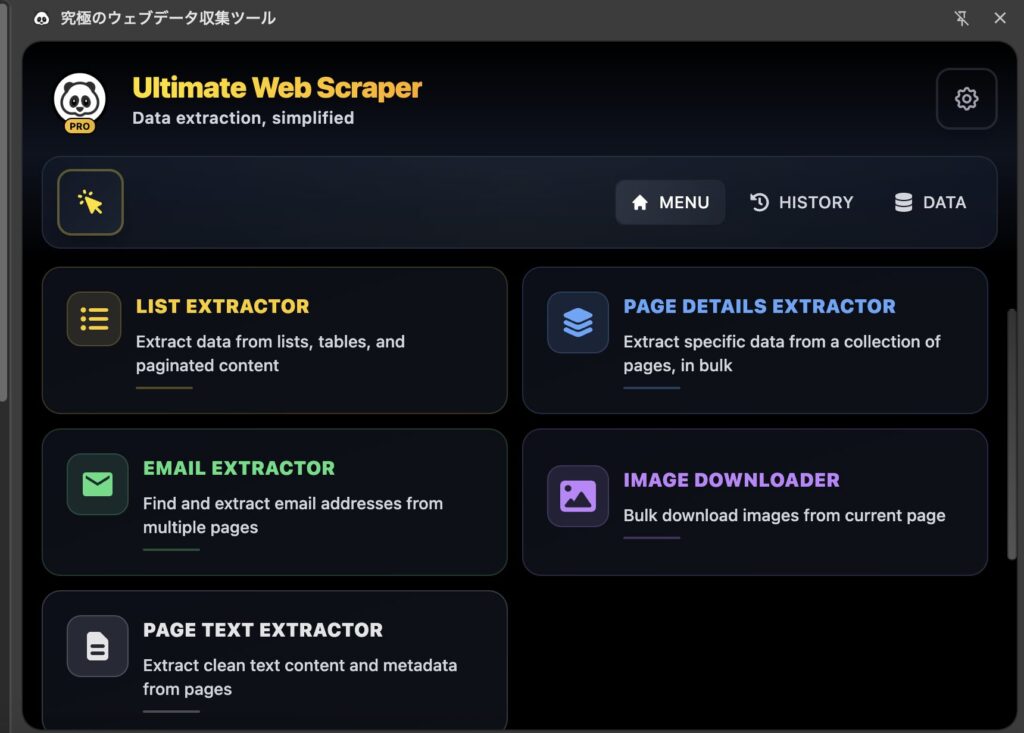
1. リスト抽出機能(List Extractor)
検索結果、商品リスト、テーブルデータなどの構造化されたデータを自動で認識し、一括抽出します。ページネーション(複数ページ)にも対応し、大量のデータを効率的に収集できます。
2. ページ詳細抽出機能(Page Details Extractor)
複数の類似ページから特定の要素(タイトル、価格、説明文など)を一括抽出します。URLリストを提供するだけで、自動的に各ページから必要なデータを収集します。
3. メール抽出機能(Email Extractor)
Webページからメールアドレスを自動検出し、リード生成に活用できます。単一ページまたは複数ページから一括でメールアドレスを抽出可能です。
4. 画像ダウンロード機能(Image Downloader)
Webサイト上の画像を自動検出し、サイズや形式別に分類して一括ダウンロードします。商品画像の収集やコンテンツ作成に便利です。
5. ページテキスト抽出機能(Page Text Extractor)
Webページから本文テキストとメタデータを抽出し、構造化されたデータとして出力します。コンテンツ分析や情報収集に最適です。
料金プランと詳細の比較
Ultimate Web Scraperは買い切り型の永続ライセンスを採用しており、一度購入すれば追加料金なしで生涯利用できます。現在、期間限定で大幅割引を実施中です。
| プラン名 | 通常価格 | 現在価格(割引率) | 使用可能デバイス数 | 対象ユーザー | 主な特徴 |
|---|---|---|---|---|---|
| Single License | $120 | $60(50%OFF) | 1ユーザー・最大1ブラウザ | 個人利用 | 全ての機能利用可能・生涯アクセス |
| Extended License | $180 | $99(45%OFF) | 1ユーザー・最大3ブラウザ | 個人・小規模チーム | 複数デバイス対応・全機能利用可能 |
| Team License | – | $49/ユーザー | 最低5ユーザー・ユーザーあたり3ブラウザ | 企業・大規模チーム | チーム管理機能・優先サポート |
おすすめのプランは…
- 個人利用 → Single License($60)
- 複数デバイス利用 → Extended License($99)
- チーム利用(5名以上) → Team License($49/ユーザー)
ライセンスが買い切りのため、セール中の今がお得です!
インストール方法
Ultimate Web ScraperのインストールはChrome Web Storeから簡単に行えます。
以下の手順に従ってください。
1. Chrome Web Storeにアクセス
Google Chromeブラウザを開き、Chrome Web Storeの「Ultimate Web Scraper」ページにアクセスします。
https://chromewebstore.google.com/detail/ultimate-web-scraper/pdeldjlcnhallaapdggcmhpailpnnkmg
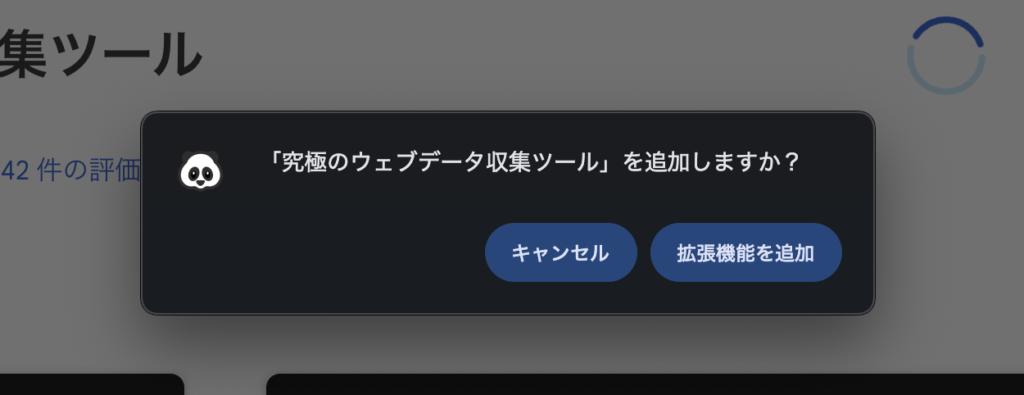
2. 拡張機能を追加
「Chromeに追加」ボタンをクリックし、確認ダイアログで「拡張機能を追加」をクリックします。

3. インストール完了確認
ブラウザの右上にUltimate Web Scraperのアイコンが表示されれば、インストール完了です。
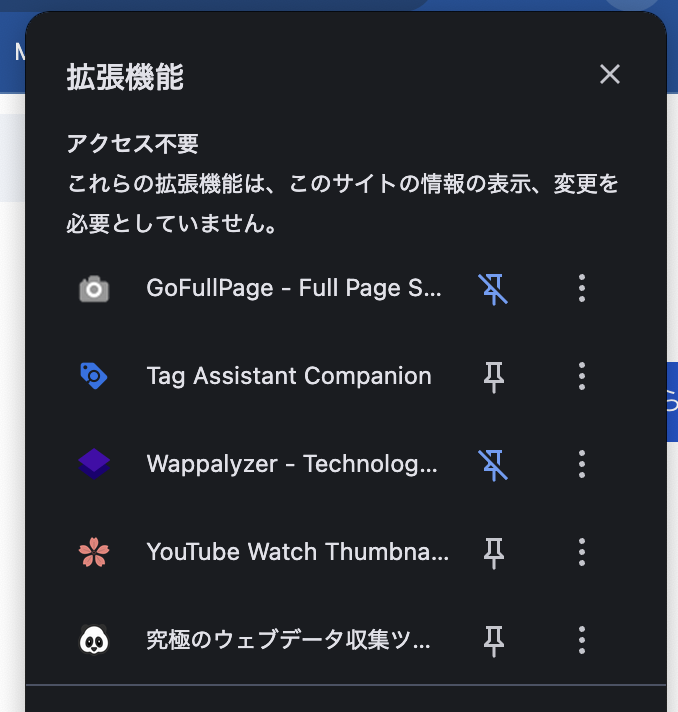
常にプラグインを表示させたい場合は、ピンを1度クリックすることでピン留めすることができます。
アクティベーション方法
無料版でも基本機能は利用できますが、全機能を使用するには有料ライセンスのアクティベーションが必要です。
1. ライセンス購入
「公式サイト(https://ultimatewebscraper.com/pricing)」にアクセスし、希望するプランを購入し、ライセンスキーを取得します。

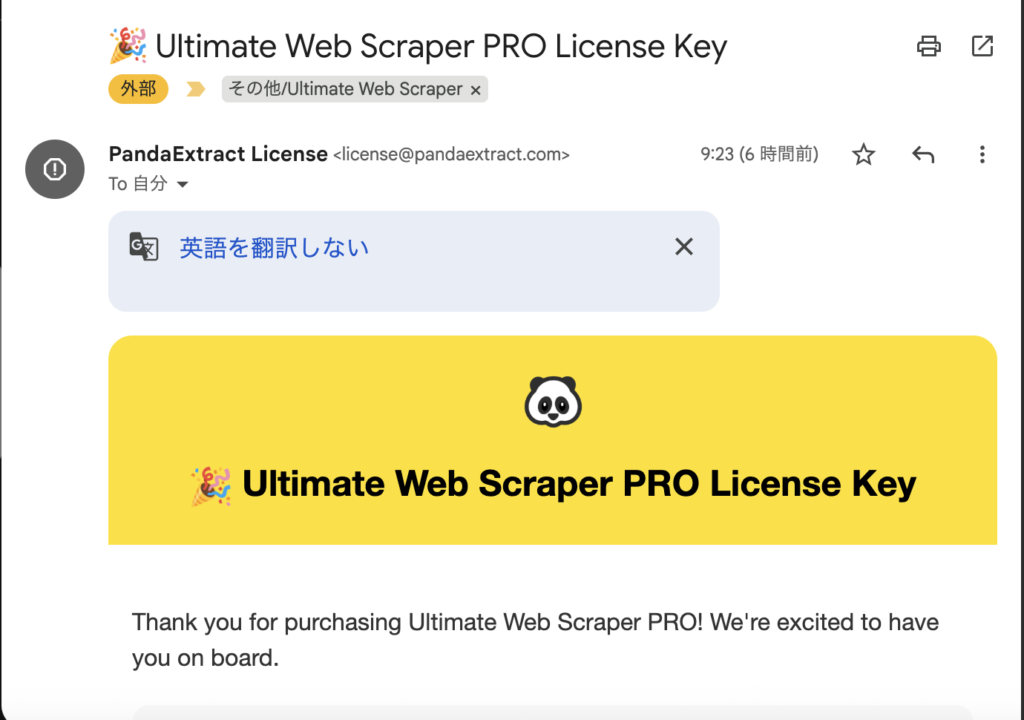
購入が完了すると、メールで「ライセンスキー」が送られてくるので、控えておきます。
(以下のようなメールが届き、下の方にライセンスキーが書かれています)
2. 拡張機能を開き、設定画面へ移動
ブラウザ右上のUltimate Web Scraperアイコンをクリックして拡張機能を開き、右上の歯車ボタンをクリックして設定画面へ移動します。
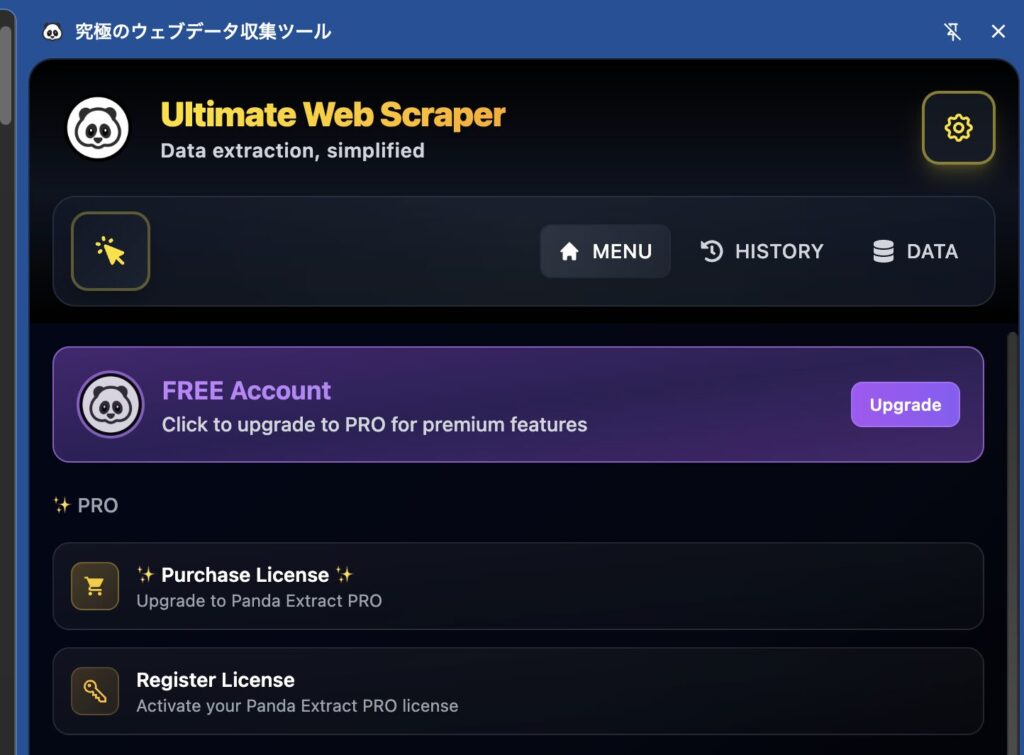
その後、「Register License」の項目をクリックします。
3. ライセンスキー入力
設定画面またはライセンス入力画面で、購入時にメールで受け取ったライセンスキーを入力します。
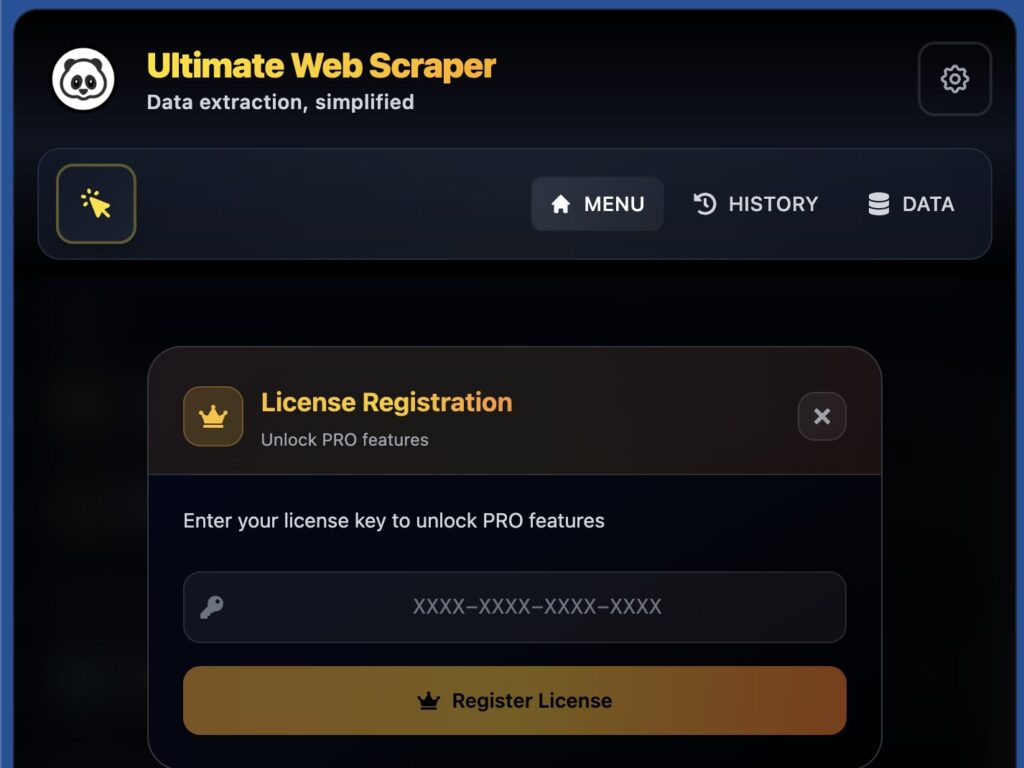
4. アクティベーション完了
「Activate」または「アクティベート」ボタンをクリックして、ライセンスを有効化します。成功すると全機能が利用可能になります。
実際の使い方:5つの機能別詳細ガイド
リスト抽出機能の使い方
最も人気の高い機能で、Google Maps、Amazon商品リスト、検索結果などを簡単に抽出できます。
(今回は例として、Amazon上で販売されている、「アサヒスーパードライ」の商品を一覧で取得してみたいと思います)
手順
抽出したいリストが表示されているWebページを開き、「Ultimate Web Scraper」を立ち上げます。
(アサヒスーパードライと検索した状態のページを開いています。)
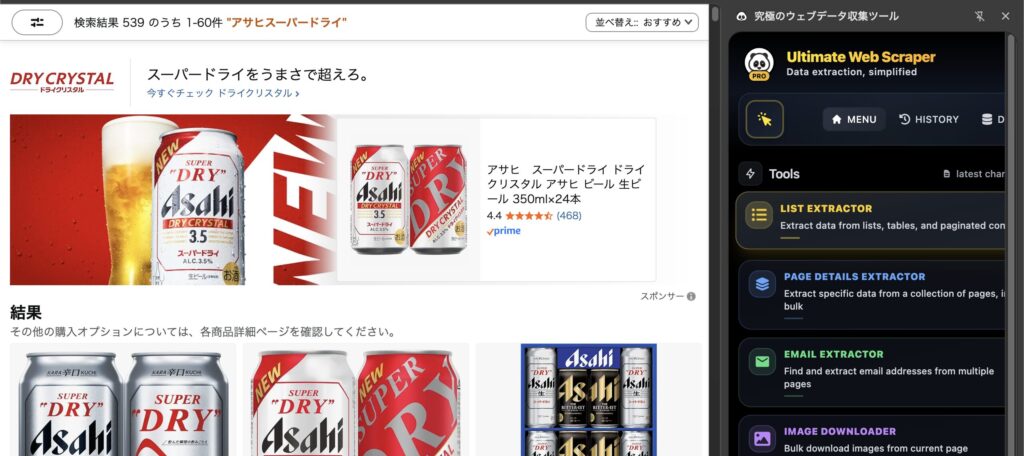
「List Extractor」を選択し、「1. Select List」をクリック。
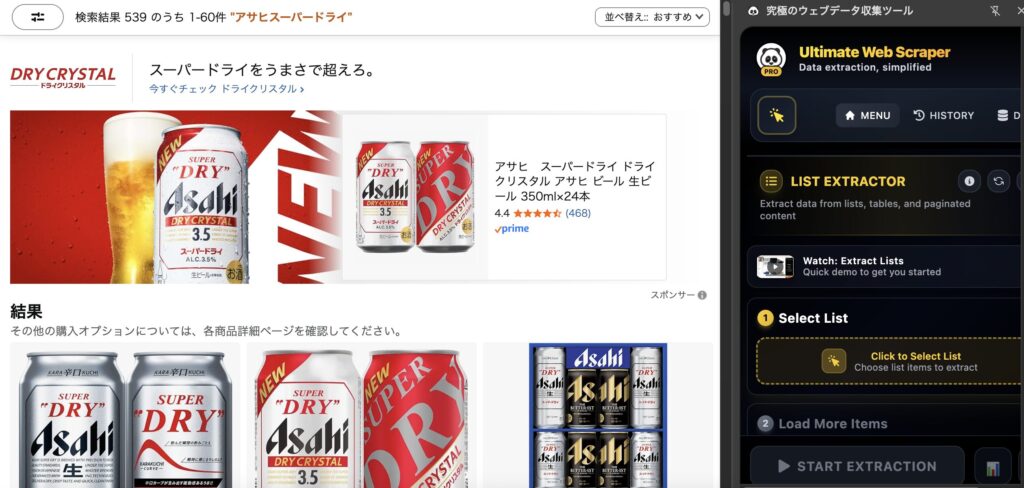
リスト上にカーソルを移動させて、黄色い枠で囲われたことを確認したらその部分をクリックします。
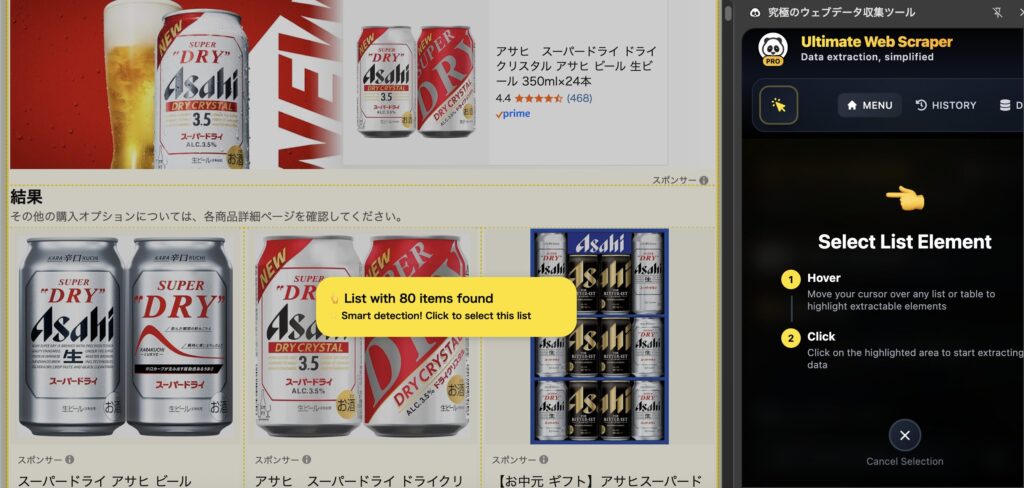
自動でデータが抽出され、1ページ目の情報がテーブル形式で表示されます。ウィンドウをバツで閉じます。
(余計な情報も入ってしまいますが、全て抽出したのちに整理すればOKなので、一旦そのままにします。)
画面を戻り、「2. Load More Items」を確認します。
「Pagenation」をクリックします。以下のようにページ内のナビゲーションの「次へ」ボタンをクリックして進みます。
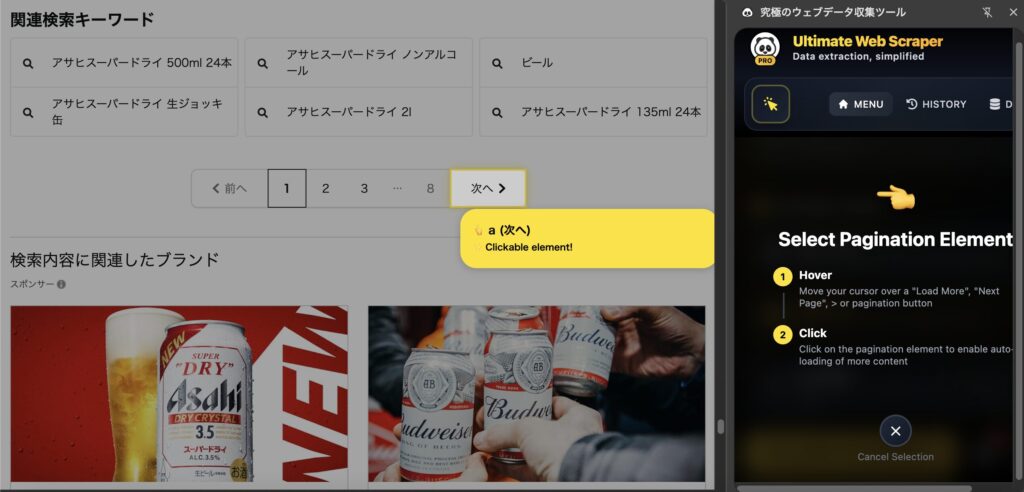
これで準備完了です!
画面右下の「START EXTRACTION」をクリックすることで、スクレイピングが作動します!
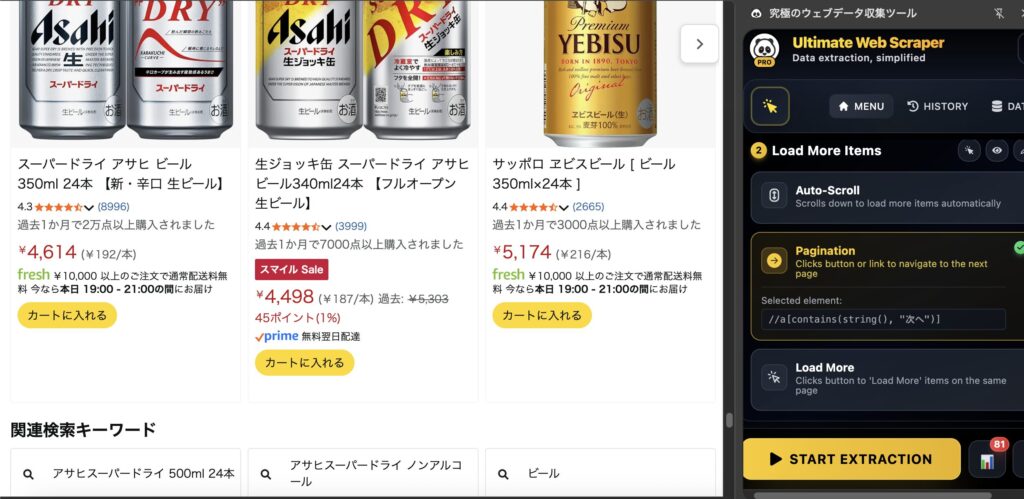
動作が完了すると、以下のように表示され、「VIEW DATA」をクリックすると抽出結果を見ることができます!
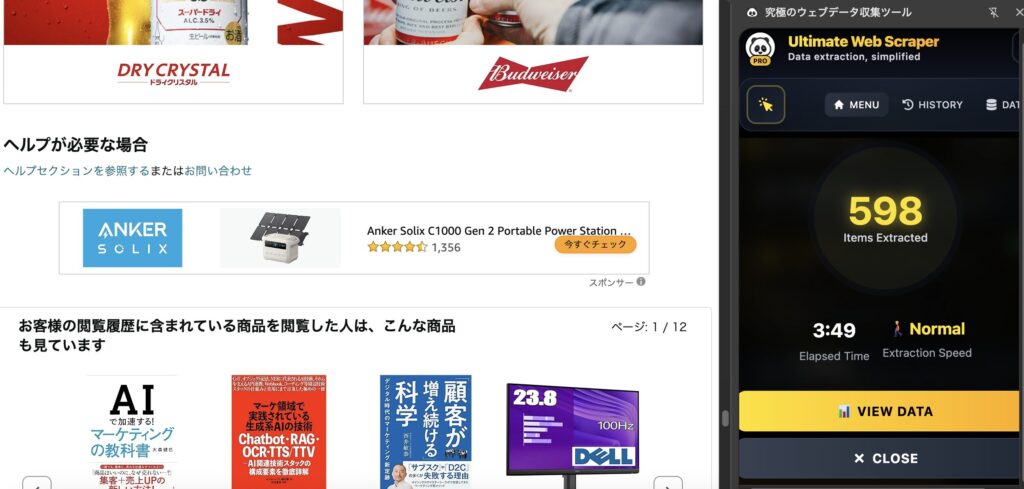
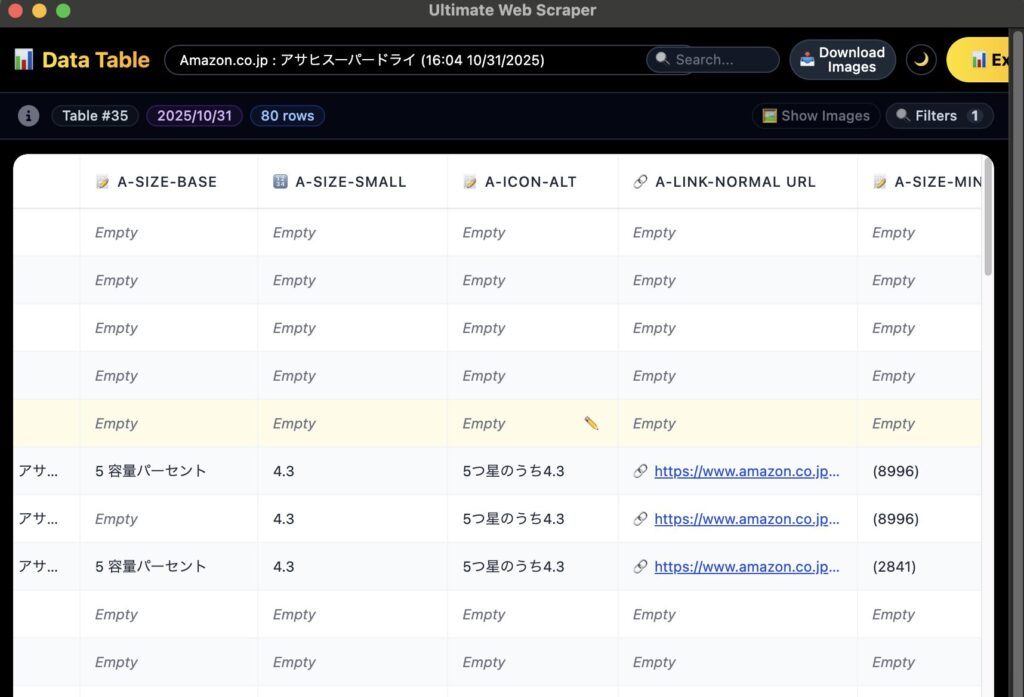
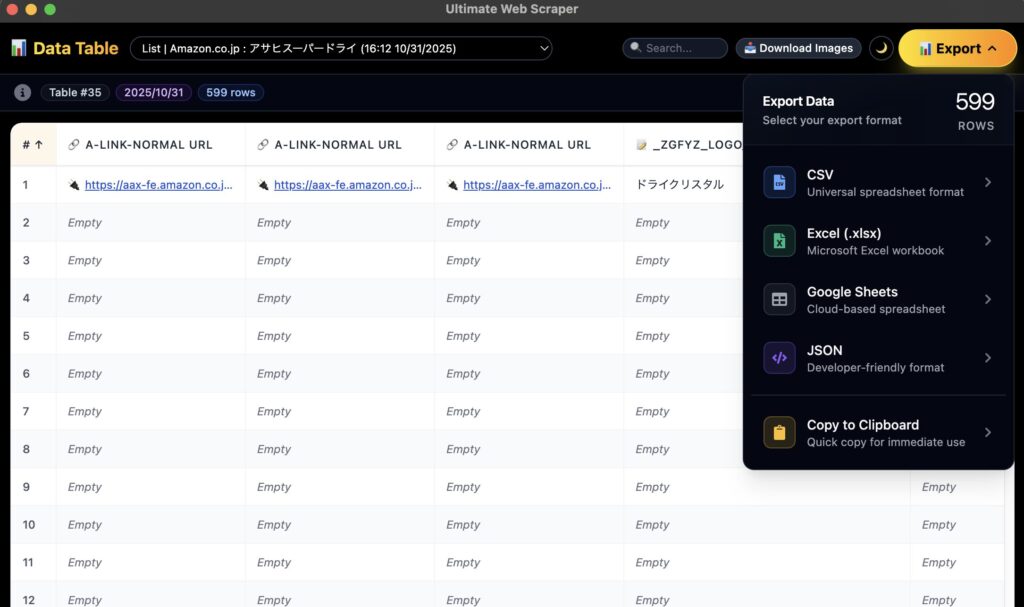
抽出したテーブルの一覧を見ることができ、
かつ右上の「Export」ボタンから、CSVやエクセルデータといった形式でダウンロードをすることもできます。
ページ詳細抽出機能の使い方
複数のページから同じ要素(価格、タイトル、説明など)を一括で抽出する機能です。
手順
- 「Page Details Extractor」を選択
- 抽出したいページのURLリストをCSVでアップロード
- サンプルページで抽出したい要素をクリックして指定
- 「Extract」ボタンで全ページから一括抽出開始
- 完了後、結果をダウンロード
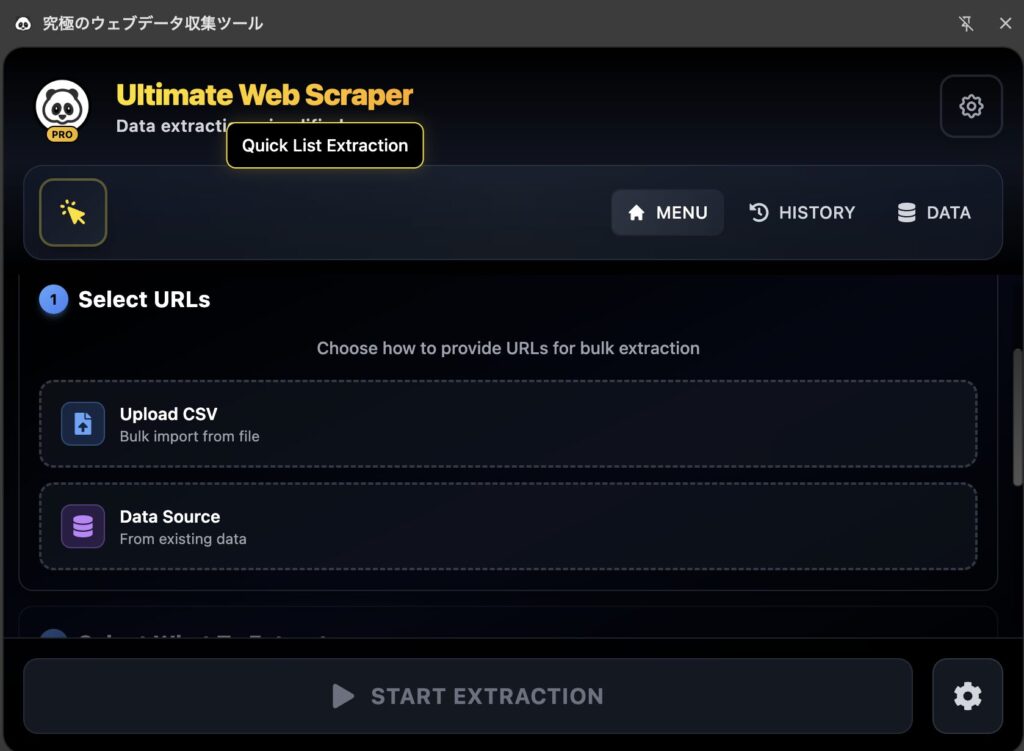
メール抽出機能の使い方
リード生成に最適な機能で、Webページからメールアドレスを自動検出します。
手順
- 「Email Extractor」を選択
- 単一ページの場合:「Scan Current Page」をクリック
- 複数ページの場合:URLリストをCSVでアップロード
- ディープスキャンオプションを有効にして詳細検索
- 検出されたメールアドレスを確認・エクスポート
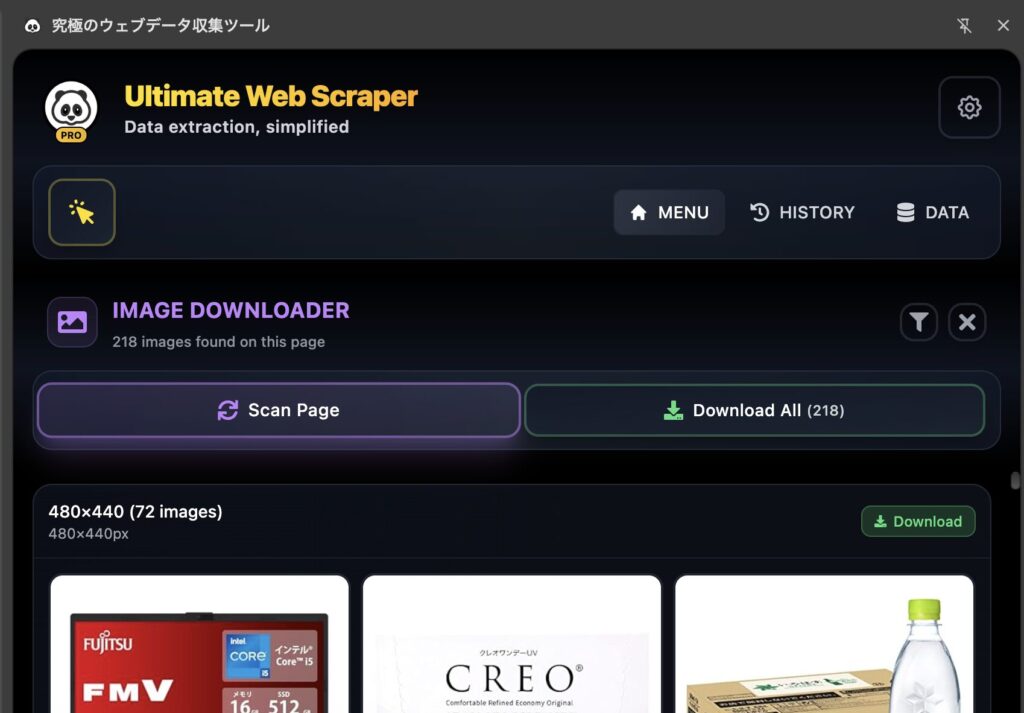
画像ダウンロード機能の使い方
Webサイトから画像を効率的に収集できる機能です。
手順
- 「Image Downloader」を選択
- 自動でページ内の画像を検出・分類
- サイズ、形式別に画像をフィルタリング
- ダウンロードしたい画像を選択
- 「Download Selected」で一括ダウンロード
ページテキスト抽出機能の使い方
Webページの本文テキストとメタデータを構造化して抽出します。
手順
- 「Page Text Extractor」を選択
- 抽出したいページのURLリストをアップロード
- 抽出オプション(メタデータ含むかどうか)を設定
- 「Extract Text」で抽出開始
- 結果を構造化データとしてエクスポート
実践的な活用事例
1. Google Maps(ローカルビジネス情報収集)
使用例:「東京 カフェ」で検索した結果から店舗名、住所、電話番号、評価を一括抽出
活用シーン:営業リスト作成、競合調査、マーケティングリサーチ
2. Amazon(商品情報収集)
使用例:特定カテゴリの商品一覧から商品名、価格、レビュー評価を抽出
活用シーン:価格比較、市場調査、競合分析
3. Airbnb(宿泊施設情報)
使用例:特定エリアの宿泊施設リストから料金、評価、アメニティを収集
活用シーン:旅行計画、投資分析、競合調査
4. LinkedIn(リード生成)
使用例:業界関係者のプロフィール情報とコンタクト先を収集
活用シーン:B2Bマーケティング、採用活動、ネットワーキング
よくある質問(FAQ)
Q1: Ultimate Web Scraperは無料で使えますか?
A: 基本機能は無料で利用できますが、高度な機能(複数ページ一括抽出、メール抽出など)には有料ライセンスが必要です。
Q2: ChromeとEdge以外のブラウザでも使用できますか?
A: 現在、Chrome、Edge、Braveブラウザに対応しています。Firefox版は開発中です。
Q3: 法的な問題はありませんか?
A: 公開されている情報の収集は一般的に問題ありませんが、各サイトの利用規約を確認し、適切な利用頻度を守ることが重要です。
Q4: 大量データの抽出でブラウザが重くなりませんか?
A: Ultimate Web Scraperは効率的な処理設計により、ブラウザへの負荷を最小限に抑えています。
Q5: サポートはありますか?
A: 有料ライセンス購入者には優先サポートが提供されます。support@ultimatewebscraper.com にお問い合わせください。
Q6: ライセンスは他の人と共有できますか?
A: 各ライセンスは指定されたユーザー数・デバイス数での利用に限定されており、無断共有は利用規約違反となります。
まとめ
Ultimate Web Scraperは、プログラミング知識不要で高度なWebスクレイピングを実現する優秀なツールです。AI搭載による高精度な抽出機能、直感的な操作性、豊富な出力形式対応により、個人から企業まで幅広いニーズに対応します。
Ultimate Web Scraperを選ぶべき理由
- ✅ ノーコードで誰でも簡単に使える
- ✅ 買い切り型で月額料金不要
- ✅ 5つの専門機能であらゆるデータ抽出に対応
- ✅ 現在50%OFFのお得な価格設定
- ✅ 11,282人以上のユーザーに信頼されている実績
データドリブンな意思決定が重要な現代において、効率的なデータ収集は競争優位性を生み出します。Ultimate Web Scraperを活用して、作業の効率化を目指しましょう!!